分层模型
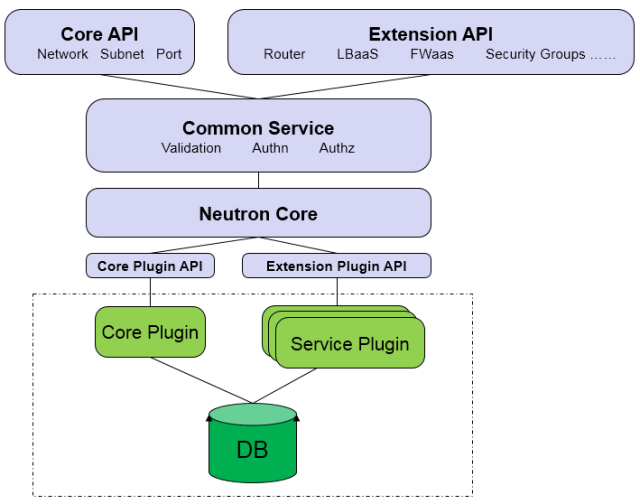
Core API
对外提供管理 network, subnet 和 port 的 RESTful API。
Extension API
对外提供管理 router, load balance, firewall 等资源 的 RESTful API。
Commnon Service
认证和校验 API 请求。
Neutron Core
Neutron server 的核心处理程序,通过调用相应的 Plugin 处理请求。
Core Plugin API
定义了 Core Plgin 的抽象功能集合,Neutron Core 通过该 API 调用相应的 Core Plgin。
Extension Plugin API
定义了 Service Plgin 的抽象功能集合,Neutron Core 通过该 API 调用相应的 Service Plgin。
Core Plugin
实现了 Core Plugin API,在数据库中维护 network, subnet 和 port 的状态,并负责调用相应的 agent 在 network provider 上执行相关操作,比如创建 network。
Service Plugin
实现了 Extension Plugin API,在数据库中维护 router, load balance, security group 等资源的状态,并负责调用相应的 agent 在 network provider 上执行相关操作,比如创建 router。
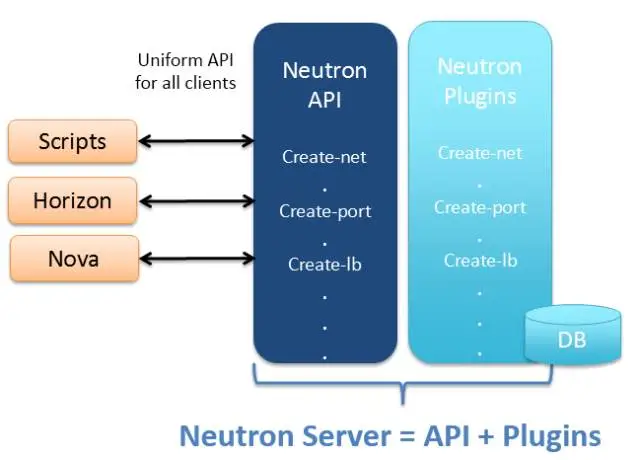
归纳起来,Neutron Server 包括两部分:
- 提供 API 服务。
- 运行 Plugin。
即 Neutron Server = API + Plugins
多种 network provider
先讨论一个简单的场景:在 Neutorn 中使用 linux bridge 这一种 network provider。
根据 Neutron Server 的分层模型,我们需要实现两个东西:linux bridge core plugin 和 linux bridge agent。
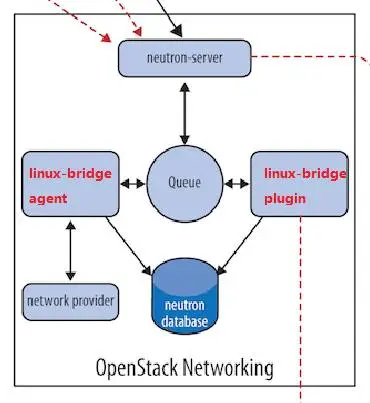
linux bridge core plugin
- 与 neutron server 一起运行。
- 实现了 core plugin API。
- 负责维护数据库信息。
- 通知 linux bridge agent 实现具体的网络功能。
linux bridge agent
- 在计算节点和网络节点(或控制节点)上运行。
- 接收来自 plugin 的请求。
- 通过配置本节点上的 linux bridge 实现 neutron 网络功能。
同样的道理,如果要支持 Open vSwitch,只需要实现 Open vSwitch plugin 和 Open vSwitch agent。
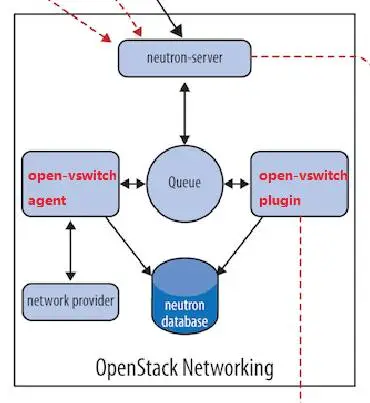
Neutron 可以通过开发不同的 plugin 和 agent 支持不同的网络技术。随着支持的 network provider 数量的增加,有两个突出的问题:
- 只能在 OpenStack 中使用一种 core plugin,多种 network provider 无法共存。
- 不同 plugin 之间存在大量重复代码,开发新的 plugin 工作量大。
ML2 plugin
ML2 功能
ML2 作为新一代的 core plugin,提供了一个框架,允许在 OpenStack 网络中同时使用多种 Layer 2 网络技术,不同的节点可以使用不同的网络实现机制。
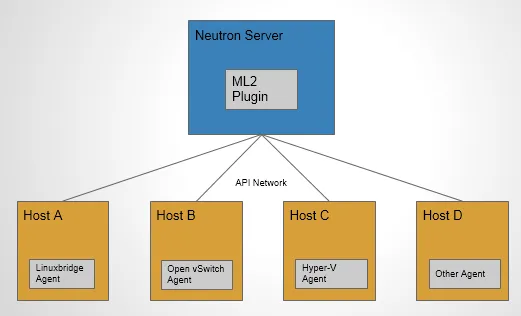
如上图所示,采用 ML2 plugin 后,可以在不同节点上分别部署 linux bridge agent, open vswitch agent, hyper-v agent 或其他第三方 agent。
ML2 不但支持异构部署方案,同时能够与现有的 agent 无缝集成:以前用的 agent 不需要变,只需要将 Neutron server 上的传统 core plugin 替换为 ML2。
有了 ML2,要支持新的 network provider 就变得简单多了:无需从头开发 core plugin,只需要开发相应的 mechanism driver,大大减少了要编写和维护的代码。
ML2 架构
ML2 对二层网络进行抽象和建模,引入了 type driver 和 mechansim driver。这两类 driver 解耦了 Neutron 所支持的网络类型(type)与访问这些网络类型的机制(mechanism),其结果就是使得 ML2 具有非常好的弹性,易于扩展,能够灵活支持多种 type 和 mechanism。
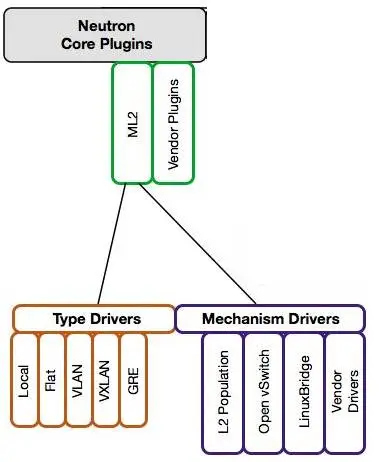
Type Driver
type driver 负责维护网络类型的状态,执行验证,创建网络等。 ML2 支持的网络类型包括 Local, Flat, Vlan, VxLan 和 GRE。
Mechansim Driver
mechanism driver 负责获取由 type driver 维护的网络状态,并确保在相应的网络设备(物理或虚拟)上正确实现这些状态。
type 和 mechanisim 都太抽象,现在我们举一个具体的例子: type driver 为 vlan,mechansim driver 为 linux bridge,我们要完成的操作是创建 network vlan100,那么:
- vlan type driver 会确保将 vlan100 的信息保存到 Neutron 数据库中,包括 network 的名称,vlan ID 等。
- linux bridge mechanism driver 会确保各节点上的 linux brige agent 在物理网卡上创建 ID 为 100 的 vlan 设备 和 brige 设备,并将两者进行桥接。
mechanism driver 有三种类型:
- Agent-based:包括 linux bridge, open vswitch 等。
- Controller-based:包括 OpenDaylight, VMWare NSX 等。
- 基于物理交换机:包括 Cisco Nexus, Arista, Mellanox 等。 比如前面那个例子如果换成 Cisco 的 mechanism driver,则会在 Cisco 物理交换机的指定 trunk 端口上添加 vlan100。
linux bridge 和 open vswitch 的 ML2 mechanism driver 作用是配置各节点上的虚拟交换机。L2 population driver 作用是优化和限制 overlay 网络中的广播流量。 vxlan 和 gre 都属于 overlay 网络。